When consulting for large firms, where the existence of copious amounts of test data is established, it makes it very easy to realise the potential of any prototype or greenfield work very quickly. Be the focus on UI or the need for extensive e2e test coverage, having access to streams of data is invaluable. When dealing with smaller scale projects in which the creation of the data itself is also new, being able to quickly create enough test data to make any prototype/ demo/ early testing of any worth is of massive value.
There are plenty of sources of mock data creation and I don’t intend to go into any review of these in this post, Instead, I wanted to cover off a little quirk I noticed when using Mongo Db as my data engine and creating mock data with guids as they’re Id. It turned out a little more complex than I first anticipated.
NoSql/ Document-based databases often prefer to rely on object identities in the form a uid, unlike Sql Server which will often use a sequential number seed. When creating the document in dotnet code, developers will usually map this uid to a System.Guid. No surprises so far.
Using my MongoDb nuget package, I can quickly knock up a web api prototype that provides basic Get/ Get by Id/ Post/ Put and Delete operations on a Mongo Db using the following class as an example:
// from AgileTea.Document.Persistence nuget library
public abstract class IndexedEntityBase
{
public Guid Id { get; set; }
}
public class Client : IndexedEntityBase
{
public string LastName { get; set; } = default!;
public string FirstNames { get; set; } = default!;
public string? Title { get; set; }
public string Salutation { get; set; } = default!;
public Gender Gender { get; set; }
public string DateOfBirth { get; set; }
public ClientContactDetails ContactDetails { get; set; } = default!;
}
public class ClientContactDetails
{
public string? Email { get; set; }
public string? Landline { get; set; }
public string? Mobile { get; set; }
}
Set up a SwaggerUI for the web api and we’re good to spin up the api and try adding a few documents, getting all, by id… etc.
But after trying it out with 3 documents it gets a bit boring. I want to add 1000 documents in and do so in the quickest way, so I turn to Mockaroo.com – a mock data generator site. Very quickly I can a mapping for my client class and generate 1000 documents:
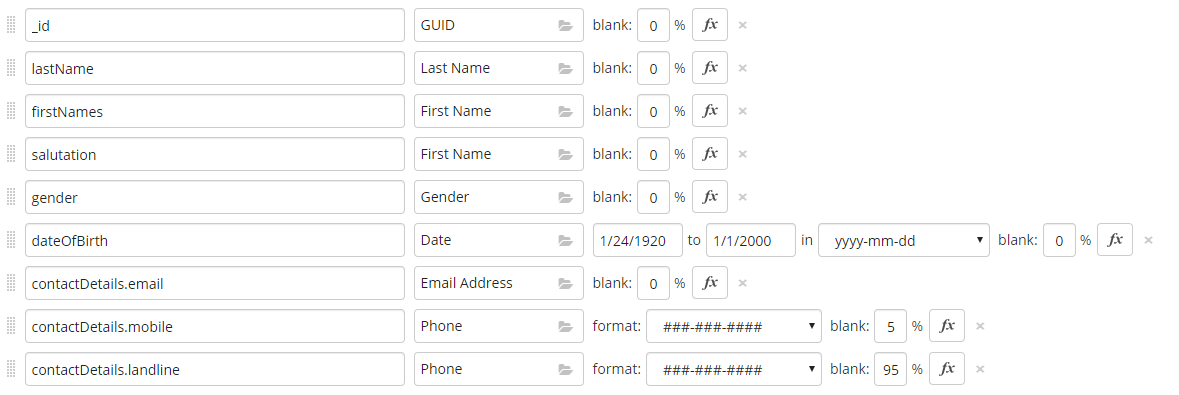
I can save this out to a json file and then use whatever MongoDb tool I choose to import the documents. In this case, I found the import option in the Compass client was fine for the job. I went my 1000 documents and now had 1003 to work with. Back to the Api, I tried a quick test to see if I could locate a document by Id and, boom, no result. After a few minutes of wondering how I could have introduced a bug in the code I went back to the documents I had manually created to find these were returned by id without issue. That’s when i noticed the difference between these documents and those created by mockaroo.
My mocked data displayed as expected:
{
"_id": "9668cde8-594b-4d1d-bd7a-02f2012f75d1",
"firstNames": "Britt",
"lastName": "Walkley",
"title": "Ms",
"salutation": "Sybila",
"gender": "Female",
"dateOfBirth": "1953-11-04",
"contactDetails": {
"email": "swalkleyrp@upenn.edu",
"mobile": "645-426-6612",
"landline": "(720) 2878269"
}
}
The data that was inserted via my code though showed a difference in the structure of the _id:
{
"_id": {
"$binary": {
"base64": "oAwP1PRT60Sw42Lc12l12g==",
"subType": "04"
}
},
"lastName": "Stollhofer",
"firstNames": "Ibrahim",
"salutation": "Ibra",
"gender": "Male",
"dateOfBirth": "1971-05-26",
"contactDetails": {
"email": "istollhofere@meetup.com",
"mobile": "375-764-6604",
"landline": null
}
}
I’d seen this form of _id before in Mongo so knew straight way that this was why I was not seeing a match with my mocked data. Each guid is transformed on insertion for performance and portability gains and my simple copy and paste bypassed this. The next challenge was to work what transformation occurs to the guid.
Guid Convention
First up was the settings I had chosen for my Mongo Options. The CSharp MongoDb Driver defaults to C# legacy convention (CSUUID) but I had switched mine to the more standard UUID convention. Not as fast as the native MongoDb ObjectId but compatible with other databases so preferred.
Base64 encoding
The next clue is in the data – a base64 encoding of the value. However it’s clear to see that the values shown (2 chars) is shorter than a GUID (36 chars), and a base64 encoding of a guid as a string would create 48 chars so it wasn’t going to be as straight forward as that.
I would like to say that at this point, I simply traced the MongoDb Driver code on Github and worked out exactly what was happening to my guid but, without an obvious method to start with, I quickly got lost. I could have cloned the code and stepped through but, fortunately for me, I had a few pointers. I knew I was using Microsoft’s UUID version of a GUI and, that the shortening of the end result was down to as base63 encoding of binary representation of the GUID, not the user-friendly string version.
Ruby
Never used Ruby before but it turns out Mockaroo do use it within their mapping generation so, if I wanted to use them to create my data, I had to work out how convert my guid to a byte array using Ruby. The following Stackoverflow post has an excellent answer on how to do this as well as some expert insight into the make up of the Microsoft Guid – thank you Stefan! In short, the following needs to be done to a Guid:
- Split the Guid into its separate hex-strings by splitting on the hyphen
- Convert each hex string into bytes
- Microsoft use a mixed-endian format where the first 3 parts are little-endian and the last 2 are big-endian. We need it all in big-endian format so the first three parts need to have the bytes reversed to make them big-endian.
In ruby, this boils down to the following:
guid = '9668cde8-594b-4d1d-bd7a-02f2012f75d1'
#=> create 5 separate strings
guidParts = guid.split(-)
#=> convert 5 hex strings into array of bytes
guidPartsAsBytes = guidParts.pack('H* H* H* H* H*')
#=> separate out the first 3 binary parts where 1st is 32bits little-endian (<) and second and third are 16 bits little-endian (<)
unpackedBinaryParts = guidPartsAsBytes.unpack('L< S< S< A*')
#=> reverse the endian form of the first three components and repack
reverseEndians = unpackedBinaryParts.pack('L> S> S> A*')
Now we have the bytes in the correct order, we can base64 encode them:
base64 = base64(reverseEndians)
Putting it altogether as a formaula for mockaroo gave me the following:
base64(this.split('-').pack('H* H* H* H* H*').unpack('L< S< S< A*').pack('L> S> S> A*'))
Using this formula along with a auto-generated GUI and the correct json structure resulted in the following mappings:
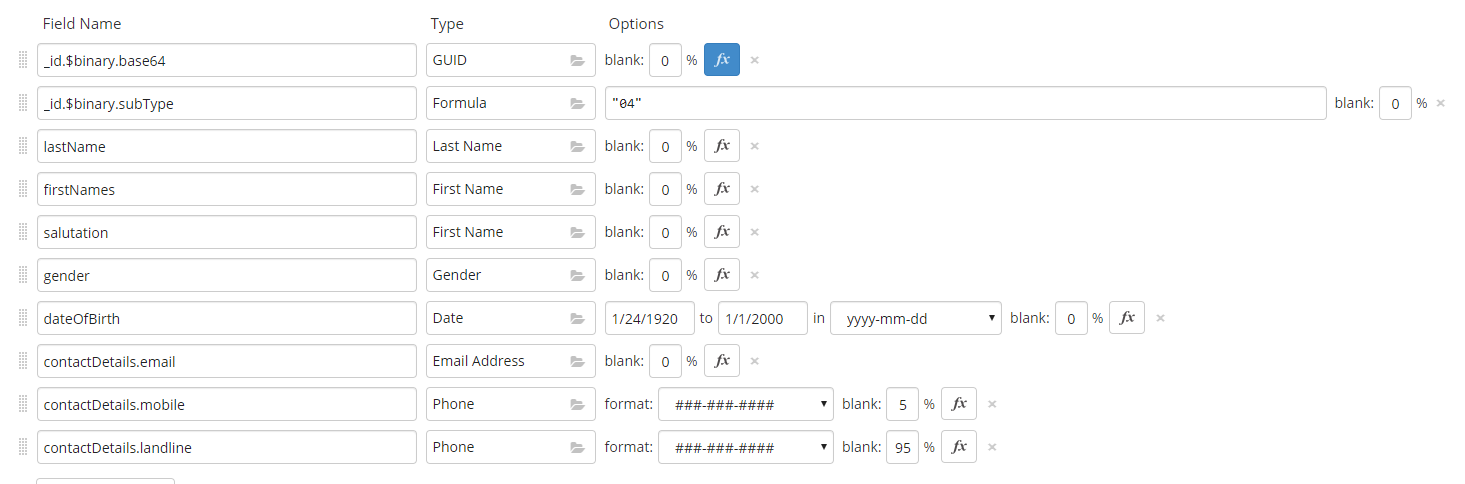
Generating my collection again and re-importing them (dropping the original collection), allowed me to prove that the GetById (and therefore any subsequent PUT or DELETE) worked as expected. A rather long detour for what I expected to be a 10 minute exercise but valuable knowledge for me next time I want to mock some Mongo data.
0 Comments